Od piwa głowa się piwa, a kto gra w karty, ten ma łeb obdarty. A jednak zdecydowaliśmy się udostępnić kolejny już kurs leksykalny poświęcony tematyce karcianej na platformy Anki, Memrise i Quizlet. Przedmiotem tej niezwykle obszernej bazy, na którą składa się 748 haseł, jest niesamowicie interesująca i rozwijająca gra, a mianowicie brydż – gra, w której ważne są pamięć, matematyka, szczególnie statystyka, myślenie strategiczne oraz psychologia, w tym także kompetencje miękkie, współpraca z innymi, kreowanie języka, porozumiewanie się nim i osiąganie założonych celów.
Skomplikowane zasady gry w brydża i złożone, nie do końca przewidywalne mechanizmy w tej dyscyplinie sprawiają, że w przeciwieństwie do szachów, w których przeciętny komputer i łatwo dostępne oprogramowanie są w stanie pokonać światowego mistrza, brydż nadal opiera się analogicznym pokusom programistów i stanowi wyzwanie dla próbujących przełożyć go na algorytymiczne języki. Napisano o tym niejeden doktorat i pewnie wiele jeszcze powstanie.
Na początek studenci I roku informatyki stosowanej na Wydziale Mechanicznym Politechniki Krakowskiej Artur Lech, Marcin Lichoń i Paweł Nowak, wspierani i inspirowani przez Babcię Artura, uporządkowali leksykon ze źródeł, jakie dostarczył nam mistrz brydżowy Piotr Ludwikowski (serdecznie podziękowania) i zaimportowali go do kursów na popularnych platformach do nauki przy pomocy fiszek. Baza jest dostępna na:
W 1995 roku Bill Gates, jako gość Davida Lettermana w programie na antenie CBS, mówił o internecie jako o tej „kolejnej wielkiej rzeczy”, jaka nas czeka. Oglądając dzisiaj tę rozmowę trudno się zdecydować, czy jest wizjonerska, czy infantylnie śmieszna, trywialna (w końcu Late Show with David Letterman było programem rozrywkowym), ale nie ulega wątpliwości, że dla nas w latach dziewięćdziesiątych internet to było coś. Było to coś tak ważnego, że nikt wówczas nie miał wątpliwości, że trzeba słowo „internet” pisać wielką literą.
Nic dziwnego, że w takiej atmosferze całe pokolenie filologów, encyklopedystów i dziennikarzy jednogłośnie, bez większej dyskusji i bez cienia wątpliwości przyzwyczaiło nas do tego, że piszemy „Internet”, a nie „internet”. Pytanie, czy nadal tak jest, i czy aby na pewno jest tak w języku angielskim. Wielu moich studentów trafia na studia informatyczne z wyniesionym z liceum lub technikum przekonaniem, że tak. Pisownię małą literą uważają za błędną. Tymczasem sprawa nie jest wcale tak oczywista, a pisownia wielką literą, aczkolwiek dopuszczalna i nadal spotykana, staje się coraz rzadsza. Zwolennicy takiej pisowni stoją poza tym tak naprawdę na przegranej pozycji, bo pisownia „Internet” z czasem odejdzie do lamusa, podobnie jak mało kto pamięta dziś o tym, że rzeczownik „radio” w języku polskim pierwotnie uważany był za nieodmienny i nie podlegał deklinacji.
Wydaje się, że nie ma żadnych logicznych przesłanek, by słowo „internet” pisać wielką literą. Najczęściej używamy tego słowa w znaczeniu bardzo analogicznym do słów „radio” czy „telewizja”, dla określenia środka przekazu informacji. „Znalazłem coś w internecie”, podobnie jak „usłyszałem w radiu” czy „zobaczyłem w telewizji”. Nie ma zatem żadnego racjonalnego powodu, by wyrazy „internet”, „web” czy „net” pisać wielką literą. Dał temu bardzo mocno wyraz Tony Long na łamach Wired jeszcze w 2004 roku. Wprawdzie wyprzedził nieco swoje czasy, bo po przejęciu Wired przez Condé Nast w 2006 roku magazyn powrócił do pisowni „Internet”, nie trwało to jednak długo. Dziś internetu pisanego wielką literą na próżno byłoby szukać nie tylko w Wired, ale w większości prasy technicznej i komputerowej
W tradycyjnym ujęciu, słowo „internet” powinno być pisane wielką literą, aby wyjaśnić różnicę w znaczeniu między Internetem (globalną siecią, która wyewoluowała z ARPANET, wczesnej sieci Pentagonu), a jakimkolwiek ogólnym internetem lub siecią komputerową łączącą wiele mniejszych sieci. Z taką interpretacją można się do dzisiaj spotkać w niektórych słownikach. Z czasem jednak „internet” i „web” zmieniły się – poprzez powszechne użycie – z rzeczowników własnych – unikalnych, nazwanych jednostek – w rzeczowniki ogólne. Większość osób spoza wtajemniczonego kręgu specjalistów nie jest w ogóle świadoma istnienia jakiegokolwiek internetu innego niż ten, którego wszyscy codziennie używamy – to rozróżnienie nie ma już znaczenia. A dla wielu młodszych ludzi, którzy dorastali z tą technologią, internet sam w sobie jest czymś zwyczajnym, takim jak telefon, telewizja czy radio. Niektórzy komentatorzy uważają, że pisownia słowa „internet” małą literą stała się bardziej naturalna dla większości Amerykanów (i nie tylko) poprzez świadome i celowe użycie małej litery „i” w produktach marki Apple (iPhone, iPad, iOS itd.).
W języku angielskim mnóstwo jest przykładów dekapitalizacji i uproszczenia pisowni pospolitych wyrazów, które pierwotnie weszły do języka jako nazwy własne, oznaczające coś unikalnego. Procesom tym ulegają nie tylko wchodzące do powszechnego użytku słowa z dziedziny technologii, jak „homepage”, „online”, „email”, „website” (niegdyś „Home page”, „on-line”, „E-mail”, „Web site”), ale także ogólne terminy pochodzące od dawnych nazw marek, jak frisbee, bandaid, velcro, czy też od akronimów (mało kto pewnie wie czy pamięta, że „scuba” pochodzi od „Self-Contained Underwater Breathing Apparatus”).
Gwóźdź do trumny Internetu wbito chyba w roku 2016. W artykule z 1 czerwca tego rokuNew York Times ogłasza oficjalny „koniec Internetu” i nadejście „internetu”. Nie jest to zresztą jednostronna, odosobniona decyzja tego dziennika, ale reakcja na ogłoszoną przez Associated Press zmianę w ich wytycznych dla dziennikarzy w dorocznie aktualizowanym przewodniku stylistycznym. Korpusy językowe od dawna pokazywały już wówczas tendencję wypierania pisowni wielką literą przez pisownię małą literą, Associated Press usankcjonował tylko to zjawisko i przyspieszył tempo zmian, bo za rekomendacjami AP poszły nie tylko New York Times, The Wall Street Journal, The Verge czy Wired, ale właściwie wszystkie media głównego nurtu.
Następnym razem, gdy przyjdzie Ci do głowy napisać słowo „internet” wielką literą i nie będzie to ani na początku zdania, ani w zbitce „Internet of Things” czy „Internet of Everything”, przypomnij sobie wiersz Adama Asnyka:
Trzeba z żywymi naprzód iść, Po życie sięgać nowe, A nie w uwiędłych laurów liść Z uporem stroić głowę
Wy nie cofniecie życia fal! Nic skargi nie pomogą: Bezsilne gniewy, próżny żal! Świat pójdzie swoją drogą!
Dawno nie aktualizowaliśmy naszych baz leksykalnych i specjalistycznych kursów językowych na różne platformy, ale z końcem tego semestru się to zmienia i ruszy fala udostępnień nowych rzeczy na Anki, Memrise i Quizlet. Chyba obudziliśmy się na dobre po pandemii.
Na początek zupełnie nowy, polsko-angielski zbiór słówek związanych z drukiem 3D. Autorami są Tomasz Dudara i Paweł Gałusza, studenci I roku informatyki stosowanej na Wydziale Mechanicznym Politechniki Krakowskiej. W zebranej przez nich bazie znajdują się 422 hasła związane z trójwymiarowym projektowaniem i drukowaniem, polecenia z oprogramowania CAD i słownictwo związane z własnościami materiałów.
To pierwsza wersja tej bazy, nie ma więc w niej bajerów w postaci nagrań czy ilustracji, ale jeśli okaże się komuś do czegoś przydatna, być może będzie w przyszłości udoskonalana. Baza jest dostępna na następujące platformy:
Jak co roku, kilka tygodni temu zalała mnie na LinkedInie fala powiadomień o ukończeniu studiów pierwszego stopnia przez moich byłych studentów i uzyskaniu przez nich tytułu inżyniera. I oczywiście, jak co roku, chociaż mówimy o tym na zajęciach z każdą grupą, wielu z nich zapomniało, że „engineer” to wcale nie jest po angielsku tytuł uzyskiwany po ukończeniu studiów pierwszego stopnia, tylko po prostu zawód. I że w tym znaczeniu inżynierem można być niezależnie od poziomu posiadanego wykształcenia. Pracę inżynierską może wykonywać inżynier po politechnice, magister inżynier, doktor, doktor habilitowany, profesor, ale równie dobrze można pracą inżyniera nazwać fizyczną pracę robotnika mniej wykwalifikowanego. Ba, określenie „sanitary engineer” bywa żartobliwie używane jako eufemistyczne określenie zawodu sprzątaczki lub śmieciarza.
Po studiach pierwszego stopnia w krajach anglojęzycznych otrzymuje się tytuł „bachelor”, wywodzący się z łacińskiego „baccalaureus”. W zależności od rodzaju ukończonych studiów może to być BA (bachelor of arts, studia humanistyczne) lub BSc (bachelor of science, studia ścisłe). W niektórych krajach można się (obecnie lub w przeszłości) zetknąć z tytułami dla zawężonych dziedzin nauki, np. „bachelor of engineering”, „bachelor of technology”, a także „bachelor of education”, „bachelor of laws”, „bachelor of medicine” itp.
Tytułem po ukończeniu studiów drugiego stopnia jest – odpowiadający polskiemu magistrowi – master. Master of Arts, Master of Science itd.
Ale tak jak nikt w Polsce nie powie o sobie, że otrzymał po studiach inżynierskich czy licencjackich bakalarat, tak nikt w krajach anglojęzycznych nie chwali się ukończeniem studiów i otrzymaniem tytułu „engineer”. Brzmiałoby to równie dziwacznie, jak po polsku określanie absolwenta studiów pierwszego stopnia tytułem „kawalera nauki” (dosłowne tłumaczenie angielskiego tytułu).
Warto też wiedzieć, że ponieważ w różnych krajach ustawodawca zdefiniował różne tytuły naukowe, a uniwersytety stosują rozmaite skale ocen na dyplomach, w tłumaczeniach oficjalnych (przysięgłych czy też w odpisach wydawanych przez uczelnie w językach obcych) tytułów i ocen nie tłumaczymy. Dlatego na wydanym przez Politechnikę Krakowską w języku angielskim dyplomie ukończenia studiów inżynierskich nie należy się spodziewać tytułu „engineer”, a znajdujący się tam tytuł „inżynier” nie jest niczyim błędem czy przeoczeniem.
Polecam filmy Daniela, jest rodzimym użytkownikiem języka angielskiego i aż miło go posłuchać. Znalazł na swoim dyplomie błąd w miejscu, w którym go nie ma, ale ciekaw jestem, czy zauważył, że na dyplomie naprawdę jest pewna usterka, którą część moich studentów była w stanie wytropić. Ba, jest to coś, co w jednym miejscu dyplomu jest napisane poprawnie, a w innym z błędem.
Kilkadziesiąt lat po śmierci Johna Lennona (zamach na niego, obok pierwszej pielgrzymki Jana Pawła II do Polski i zamieszek na ulicach Częstochowy w sierpniu 1980, stanowi jedno z historycznych wydarzeń, które są najwcześniejszymi wspomnieniami z mojego dzieciństwa) doczekaliśmy się w tym tygodniu premiery najnowszej i pewnie ostatniej piosenki zespołu The Beatles. Psychodeliczna ballada „Now and Then” została nagrana w domowych warunkach na kasecie magnetofonowej w 1977 roku w Nowym Jorku i była jedną z piosenek, których Lennon nigdy nie ukończył ani nie wydał komercyjnie.
Przekazana przez wdowę po Lennonie, Yoko Ono, kaseta stała się przedmiotem zainteresowania pozostałych członków zespołu The Beatles w roku 1995, ale kiepska jakość nagrania i brak możliwości odseparowania ścieżki dźwiękowej fortepianu od ścieżki wokalnej sprawiły, że prace nad wypuszczeniem singla wstrzymano, a wreszcie odłożono na półkę. Dopiero technologiczna rewolucja, jakiej świadkami jesteśmy w ostatnim czasie, i zastosowanie sztucznej inteligencji, pozwoliły doprowadzić nagranie do takiego stanu, w którym można je było wreszcie opublikować – z udziałem Paula McCartneya i Ringo Starra, ostatnich żyjących członków zespołu, z wykorzystaniem nagrań George’a Harrisona z 1995 i z dodatkowymi słowami autorstwa McCartneya.
Ale nie pisałbym o tym tutaj, gdybym nie chciał poruszyć pewnej kwestii językowej. Zauważyłem w polskich mediach, że zachwycający się niezaprzeczalnym fenomenem tej nieco infantylnej, ale miłej piosenki zza grobu i w gruncie rzeczy majstersztykiem w rodzącej się na naszych oczach sztuce deep fake’ów dziennikarze, w tym także najbardziej cenieni dziennikarze muzyczni, dopatrując się mistycznych i profetycznych talentów u Lennona, zdają się nie rozumieć tytułu piosenki albo nie zwracają uwagi na jej słowa. „Now and Then” to wprawdzie dosłownie „Teraz i wtedy”, albo – jak twierdzi Google Translate – „Teraz i później”, ale wystarczy się wsłuchać w tekst piosenki, by zrozumieć, że tutaj ma znaczenie podobne, jak we frazie „every now and then”, czy też „every now and then and again”, czyli „czasami”, „od czasu do czasu”, „sporadycznie”.
Wysłałem wczoraj moim studentom pytanie, jak rozumieją tytuł piosenki „Now and Then” i jak by go przetłumaczyli na język polski. W ciągu minuty otrzymałem odpowiedź, że „od czasu do czasu”. Może legendom polskiego dziennikarstwa muzycznego przydałaby się lekcja angielskiego u Olafa lub innego studenta Wydziału Mechanicznego Politechniki Krakowskiej? A może po prostu nie wsłuchali się w słowa piosenki, której wypuszczenie komentowali dla wszystkich polskich mediów?
Co ciekawe, DeepL radzi sobie z tym idiomem i jako pierwsze sugerowane tłumaczenie, bez podania kontekstu, proponuje „od czasu do czasu”. Ba, chociaż zwykle się pastwię nad Bingiem, tym razem Bing się w ogóle nie bawi w dwuznaczności i podaje właściwe tłumaczenie.
Ten wpis to odświeżany kotlet z 2019 roku. Jest o ostatnim roku, z jakim miałem zajęcia przed pandemią, stacjonarnie. Z niektórymi z nich spotkaliśmy się potem na studiach drugiego stopnia, już online. W tym semestrze będą bronić prace magisterskie. Jeden z tych studentów, tak mi się wydaje, jest dzisiaj moim przyjacielem. Czas płynie bezlitośnie szybko.
Z pierwszym rokiem informatyki stosowanej Wydziału Mechanicznego Politechniki Krakowskiej pobiliśmy wiele rekordów. Z żadnym rokiem dotychczas nie nurkowaliśmy na przykład dotąd podczas zajęć z angielskiego lub tuż po nich, a tymczasem dzisiaj Arek, Bartek, Krzysztof i Szymon z pierwszego roku nie tylko wskoczyli do Zalewu Nowohuckiego, ale również wprawili resztę roku w osłupienie, wyławiając z tegoż Zalewu prawdziwe… małże. W dodatku jakże okazałe.
Najbardziej dumny jestem natomiast ze studentów pierwszego roku informatyki stosowanej Wydziału Mechanicznego Politechniki Krakowskiej, ponieważ przechytrzyli kilka tygodni temu autorów zagadki tygodnia pisma New Scientist. Takie coś dotąd naprawdę nam się nie wydarzyło.
W grupie C2 i w grupie C1 czytamy New Scientist, a także kilka innych źródeł, w tym Wired, Scientific American, PC World Computer, Medium. Rozwiązujemy krzyżówki, omawiamy innowacyjne rozwiązania, oryginalne podejścia do problemów, ciekawe artykuły. O ile jednak C2 nie może się skupić na takich zagadkach, bo mają ciągle milion dygresji, komentarzy i wątpliwości mniej lub bardziej bezpośrednio dotyczących sedna sprawy, i nie udało im się rozwiązać zagadki, która jest przedmiotem niniejszego wpisu, a w grupie C1 udało się wprawdzie dojść do sedna sprawy, ale jednak zabrakło czegoś, by złapać byka za rogi, grupa B2+, najmniej zaawansowana na roku, nie tylko że znalazła odpowiedź na postawione przez magazyn pytanie, ale przechytrzyła autorów zagadki udowadniając im, że się mylą.
Kilka tygodni temu New Scientist postawił przed swoimi czytelnikami następujące wyzwanie. Załóżmy, że jakaś znudzona rzeczywistością, ambitna i pracowita kobietka postanawia napisać książkę w języku angielskim, w której wszystkie liczby całkowite od zera do plus nieskończoności zostaną wypisane w kolejności alfabetycznej. Wiadomo, że zadanie jest niewykonalne, bo liczb wypisać trzeba nieskończenie wiele, ale jednak wiadomo też, że pierwszą liczbą będzie eight.
Gdy pytałem o to studentów w różnych grupach, to eight było dość oczywistą odpowiedzią. Jaka będzie druga liczba, większość grup też wydedukowała. Będzie to eight billion. Pytanie w zagadce postawionej przez magazyn dotyczyło jednak liczby… przedostatniej.
Załóżmy, że naszej autorce znudziło się wypisywanie liczb w kolejności alfabetycznej począwszy od pierwszej, czyli tego nieszczęsnego eight. Wszystko jej ciągle się zaczyna na eight, postanawia zmienić taktykę i iść od końca. Wiadomo, że na końcu jest zero.
Pytanie magazynu brzmi, jaka liczba jest przedostatnia. Dość łatwo jest dojść do wniosku, że odpowiedź musi mieć coś wspólnego z two.
Tydzień po zadaniu tego pytania, New Scientist publikuje poprawną odpowiedź. Jest nią rzekomo two trillion two thousand two hundred and twenty-two. Dla B2+ jest dość oczywiste, że to zła odpowiedź. Ta liczba jest dość blisko końca. Ale ona nie jest przedostatnia. Ona jest trzecia od końca.
Wiecie, jaka jest prawidłowa odpowiedź? Wiecie, jaka liczba jest przedostatnia?
Ostatnie kilka tygodni poprzedniego semestru, poczynając od grudnia jeszcze, eksperymentowaliśmy z niektórymi grupami studentów ze sztuczną inteligencją, głównie tą od OpenAI, ale nie tylko. To były dość ciekawe doświadczenia, przynajmniej dla mnie, bardzo pouczające i raczej inspirujące niż przeraźliwe. W sztucznej inteligencji w rodzaju tej od OpenAI widzę raczej narzędzie, z którego należy nauczyć się korzystać, a nie zagrożenie dla ludzkości, edukacji czy nie wiadomo czego jeszcze. Z ChatGPT trzeba się nauczyć rozmawiać, ale na pewno można go wykorzystać z pożytkiem. Z tego, co wiem, studenci inżynierii medycznej na Wydziale Mechanicznym Politechniki Krakowskiej (a pewnie nie tylko oni) zaprzęgli ChatGPT do roboty na swoją korzyść i to wcale nie do ściągania czy bezmyślnego odwalania za nich roboty, tylko właśnie do nauki.
OpenAI od dłuższego czasu stanowi ulubiony temat lekturek i prezentacji zarówno na studiach pierwszego, jak i drugiego stopnia, i trzeba się nieźle nagimnastykować, by przypilnować, że tematy będą unikalne. Ale też źródeł jest obecnie tak wiele, tak wiele się o tym mówi i pisze, że nietrudno jest znaleźć coś oryginalnego, poruszającego jakiś kolejny aspekt, analizującego ten fenomen z innej perspektywy. Zamierzchłą przeszłością wydaje mi się dzień, gdy student przyszedł z lekturką o DALL-E i nie wiedział, jak się wymawia nazwę tego modelu. Dzisiaj cała lista wyrażeń i nazw związanych ze sztuczną inteligencją jest ciągle na ustach wszystkich i nikt już nie ma wątpliwości, jak to się poprawnie wymawia. Nawiasem mówiąc, jednymi z moich pierwszych eksperymentów z DALL-E było stworzenie serii bardzo realistycznych „fotografii” przedstawiających Rynek w Krośnie i w Tarnowie podczas powodzi. Kto zna oba te miasta, wie doskonale, że Rynek jest tam na wysokim wzgórzu i jest wysoce nieprawdopodobne, by kiedykolwiek został zalany, ale dla OpenAI nie stanowiło to większego problemu.
Moje bardziej intensywne zabawy z tekstem i narzędziami OpenAI zaczęły się od sprawdzania, jak OpenAI Playground poradzi sobie z napisaniem wypracowań z języka angielskiego na poziomie rozszerzonym i na poziomie dwujęzycznym, użyłem poleceń z grudniowej diagnozy przygotowanej przez Centralną Komisję Egzaminacyjną. „Pisząc” kolejne wypracowania zrozumiałem, że by wypracowanie było naprawdę dobre, trzeba nie tylko wkleić algorytmowi polecenie, ale poinstruować go, by tekst był odpowiedniej długości, by używać w nim pogłębionej, wieloaspektowej argumentacji itd. Stąd każde kolejne wypracowanie wychodziło „mi” coraz lepsze. Niezmiennie, napisanie wypracowania, za które maturzysta dostałby sporo, a może i nawet maksymalną liczbę punktów, zajmowało sztucznej inteligencji kilka sekund.
I tak na przykład „napisałem” artykuł do czasopisma młodzieżowego o akcji „Pomóż zwierzętom przetrwać zimę”:
Winter is the time of year when animals struggle to stay warm and find food. To help animals survive winter, a local high school is organizing an event called “Help Animals Survive Winter”.
The event will take place on Saturday, December 12th, and will include activities such as making bird feeders, planting trees, and collecting items to be donated to shelters and rescue organizations. The event will also include educational presentations on wildlife conservation and humane animal care.
To promote the event, the school is encouraging students and their families to share the event’s slogan and hashtag #HelpAnimalsSurviveWinter on social media. Flyers are being distributed throughout the community, and the school is also working with local media to get the word out.
This event is a great opportunity for students to learn more about how to help animals and make a difference in their local community. It’s also a great way to get involved in wildlife conservation and show solidarity for animals suffering from the cold winter weather.
We hope to see you on December 12th at the “Help Animals Survive Winter” event!
Udało mi się też „napisać” rozprawkę o dobrych i złych stronach wprowadzenia przepisu pozwalającego na uzyskanie prawa jazdy dopiero po ukończeniu dwudziestu jeden lat:
The minimum legal driving age has been a hot topic of debate for decades, and it has sparked an ongoing discussion about the pros and cons of introducing a regulation which would allow taking a driving test no sooner than at the age of 21. On one hand, there are many arguments in favor of such a solution. On the other, there are also reasons why it should not be implemented.
To begin with, there are several advantages to having such a regulation. First, it would reduce the number of young drivers on the roads, which in turn would reduce the number of accidents caused by inexperienced drivers. By introducing a legal driving age of 21, we would be ensuring that young drivers are more mature, and have the experience and knowledge necessary to drive safely. In addition, this would also lead to fewer uninsured drivers, as insurers are less likely to cover drivers under the age of 21.
On the other hand, there are also some drawbacks to introducing such a regulation. For starters, it could cause a major inconvenience for families with young adults who are in need of a vehicle. It could also be detrimental to small businesses, as it could reduce the number of potential employees who could use their own vehicle to get to work. Moreover, it could lead to an increase in public transport costs, since people would be more likely to use public transport if they are unable to drive.
In conclusion, although introducing a regulation that would allow taking a driving test no sooner than at the age of 21 could bring some advantages, there are also a number of potential drawbacks that should be taken into consideration before implementing such a law. It is important to weigh the pros and cons carefully in order to determine if such a regulation would be beneficial to society.
W powyższym, nie tylko Grammarly, ale także moi studenci potrafią znaleźć błędy. I bynajmniej nie mówię tu o amerykańskiej pisowni favor. No ale ujdzie, to są wszystko dyskusyjne sprawy. „Napisałem” też list do gazety w odpowiedzi na artykuł, którego autor twierdzi, że w życiu warto podejmować ryzyko:
To the Editor,
I read the article recently published in your newspaper stating that life is worth taking risks and I felt compelled to write a letter expressing my opinion on the matter.
Risky activities are attractive to young people, who are often unencumbered by the responsibilities of adulthood and can therefore take more risks than older people. Taking risks can lead to exciting experiences, such as bungee jumping or sky diving, or even more everyday risks such as trying out a new restaurant or applying for a job outside of one’s comfort zone. Taking risks can also be beneficial in terms of personal growth and development, as it helps people to expand their horizons and develop their skills.
I can personally attest to the benefits of taking risks. A few years ago, I left my job to travel to a foreign country, with no contacts or resources. It was a risk, but one that worked out for me. I was able to gain a new perspective on life, develop my language skills, and form new friendships. I believe this experience has made me a more confident and self-assured person.
While I believe that taking risks can be beneficial, there are certain situations where taking a risk is not advisable. If the potential downside of taking the risk outweighs the potential upside, then it is not a risk worth taking. For example, if an individual is considering making a risky investment, they should carefully analyze the available data and seek professional advice before making a decision.
In conclusion, while taking risks can be beneficial, it is important to weigh the potential costs and benefits before making a decision.
Sincerely,
[Your Name]
A także rozprawkę, w której przedstawiłem „swoją” opinię na temat potrzeby ochrony lasów i angażowania się w akcje mające zapobiegać ich wycinaniu (odnosząc się do ekologii, walorów rekreacyjnych i rozwoju infrastruktury):
Protests to protect forests are necessary in today’s world in order to ensure their preservation for the sake of ecology, recreational values and infrastructure development.
From the point of view of ecology, forests are the lungs of our planet, providing oxygen and purifying the air we breathe. They also play an important role in the water cycle, ensuring that water is available for human and ecosystem needs. In addition, forests are home to a wide variety of wildlife, from birds and butterflies to mammals and amphibians, and are essential for the preservation of our biodiversity. By protesting against deforestation, we can ensure that these benefits are maintained and that forests are not lost to logging, development or any other activity that threatens their existence.
In terms of recreational values, forests are a great source of joy and inspiration for people of all ages. They offer a place to escape the hustle and bustle of urban life and reconnect with nature, providing a sense of peace and tranquility that is often hard to find in our increasingly hectic world. In addition, forests are ideal places for outdoor activities such as hiking, camping, bird watching, fishing and more. By protesting against deforestation, we can ensure that these recreational opportunities are available to people for years to come.
Finally, when it comes to infrastructure development, forests are essential for the construction of roads, bridges and other vital infrastructure. In order to ensure that these projects are completed in a sustainable and responsible manner, it is important to protect our forests from deforestation and other activities that could harm them. Demonstrations and protests can be effective ways to raise awareness and keep these projects from going too far, thus preserving our forests for future generations.
In conclusion, protests to protect forests are essential for the sake of ecology, recreational values and infrastructure development. By taking action and speaking out against deforestation, we can ensure that these important ecosystems are preserved for future generations to enjoy.
Pozwolę sobie nie cytować wierszy, przypowieści biblijnych, bajek w stylu Hansa Christiana Andersena itp., jakie z koleżankami potworzyliśmy przy użyciu OpenAI w ramach kolejnych eksperymentów, bo chyba jednak zawierały zbyt wiele intymnych szczegółów.
W eksperymentach z ChatGPT sądziłem, że skoro na pytanie o to, czy warto studiować na Politechnice Krakowskiej, dostałem cały wykład o tym, jaka to prestiżowa uczelnia i jak to bez wątpliwości warto tu studiować, otrzymam podobną odpowiedź na pytanie o to, czy warto mieszkać w Krośnie. A tu niespodzianka:
I’m sorry, but I don’t have enough information to accurately answer your question. Krosno is a city in Poland, but I don’t know what you value in a place to live, so I can’t say if it would be a good fit for you. It would be helpful if you could provide more context or details about what you’re looking for in a place to live.
Postanowiłem – w ramach dalszych eksperymentów – „napisać” trzy wiersze o Mikołaju, który dobrze zna angielski, ale który mało co się odzywa na zajęciach z angielskiego. Poprosiłem OpenAI Playground o napisanie wierszy, które opiszą powyższą sytuację, a jednocześnie będą się kończyć szczęśliwie. Poza tym poprosiłem, by wiersze naśladowały style konkretnych poetów: Emily Dickinson, Roberta Frosta i Williama Shakespeare’a. Nie powiem, że OpenAI wspięła się na poziom wieszcza tego czy innego, ale gdyby dać komuś dopasowankę tych trzech nazwisk i poniższych trzech wierszy, osoba mająca minimalne pojęcie o literaturze anglojęzycznej dopasuje poprawnie.
Mikołaj to prawdziwy człowiek, jest moim studentem na pierwszym roku. Ale to z drugim rokiem zrobiliśmy sobie następnie bardzo ciekawy eksperyment ze sztuczną inteligencją. Zadałem im do napisania wypracowanie, niczym za dawnych czasów. Mieli napisać mail biznesowy dotyczący jakiegoś wyimaginowanego problemu i użyć poprawnie pewnej listy słów. Wymarzone zadanie dla ChatGPT, nieprawdaż? Ale umówiliśmy się, że kto chce, niech napisze przy użyciu AI, kto chce, niech się nią wesprze, a kto chce, niech napisze naprawdę sam. Potem razem czytaliśmy te wszystkie listy i dzieliliśmy się wrażeniami, czy to napisała sztuczna inteligencja czy człowiek. Następnie przepuszczaliśmy tekst przez algorytm sprawdzający, czy to ChatGPT czy nie (obecnie GPTZero) i patrzyliśmy na wyniki analizy. Następnie autor(-ka) mówili nam, czy to był tekst napisany przez nich samych, czy przez sztuczną inteligencję. Wyniki były bardzo zaskakujące, a te zajęcia – przynajmniej dla mnie, może nie dla moich studentów – były bardzo ciekawe, nawet jeśli niechcący obraziłem przy okazji Olę. Okazuje się, że można zlecić napisanie czegoś sztucznej inteligencji, potem celowo wprowadzić parę oczywistych byków, a już mechanizm weryfikujący uzna, że to na pewno człowiek, a nie maszyna, stworzył taki wadliwy tekst. Podobnie można bardzo ładnie napisany tekst uznać za wytwór sztucznej inteligencji tylko dlatego, że jest elegancki, ogładzony i poprawny.
Poniżej trzy teksty studentów z drugiego roku*, które wydają się na pierwszy rzut oka być wytworami ludzkiej kreatywności. Czy widzicie, dlaczego? Czy jesteście pewni, że na pewno nie są wspomagane AI? Obyś żył w ciekawych czasach, powiadano kiedyś. Nam wszystkim to się ziściło.
Hi Jim, There’s an opportunity we might miss if we don’t act fast enough. Someone’s done the math and the JTC stock price is said to converge down to 50% of it’s todays value by the end of the year because of the Great Fraud (yep it’s already been given a name go ahead and google it if you don’t believe me) and that is our deadline before we gather enough resources, start complete cutover of our system and make all the money we can ask for. Now, read carefully. Due to the downtime of JTC, retailers are in a big threat since JTC provides them with their bespoke parts of the appliances they sell. We are going to provide all endangered retailers with the most robust and miraculous product – IErn. Our supply chain comes from my best friend Bob Lazar who’s definitely the best pick for us because of his terrestrial company Bloto that mines the element 115 also called moscovium which is widely used to manufacture flying saucers. But to make this plan come true we need to stay focused, agile and we need to seek for every venture that’s within our scope. Fraud is an increasingly occurring threat in the retail industry and smart entrepreneurs like us should learn how to take it to our advantage. Hit me up after you read this e-mail. Wojtek
Dear Pablo, I am writing to you in order to announce that our robust chain of supply of crack cocaine is under a threat of total annihilation. Our stock of coca leaves is dwindling and it most definitely won’t last us another week. It has been increasingly more difficult to find somebody that provides good products since the government announced that all car retailers are to screen their customers as a result of recent fraud uncovered by the extraterrestrial detachment of FBI. These aliens are really agile! In the light of currently occurring circumstances, we must meet the less-than-a-week deadline I mentioned above so we can avoid any downtime. Also within scope, is an option of embracing the new reality and conducting a cutover, we will just produce crack cocaine ingredients ourselves. By the way, I hope our paths will converge in the near future so we can meet eye to eye and discuss a new deal that I lined up for us with the Chinese. We are to provide them with a totally bespoke new product for their domestic market. But this is not something I’m willing to discuss via an email. See You Later, Alligator Mike Litoris
* Każdy z powyższych maili zawiera błędy językowe i omówiliśmy je sobie na zajęciach z wszystkimi grupami, w których je czytaliśmy.
Co by nie mówić, moi studenci to cwaniaki i oni dobrze wiedzą, że sztuczna inteligencja to przyszłość, a wielu z nich czeka kariera z nią związana. I sami w sobie też są inteligentni. Pozazdrościć.
Do rodziny kursów słownictwa specjalistycznego stworzonych przez moich studentów dołączyła właśnie pozycja adresowana specjalnie dla Ukraińców. W praktyce to klon naszej polsko-angielskiej bazy słownictwa matematycznego, będącej największą tego rodzaju publicznie dostępną bazą na Memrise i na Quizlet.
Ukraińsko-angielski kurs słownictwa matematycznego zawiera 551 haseł, przetłumaczyli go i skompilowali Vladyslav Dikhtiaruk i Anastasiia Bazyshyn, studenci informatyki stosowanej na Wydziale Mechanicznym Politechniki Krakowskiej, korpus przejrzało i zgłosiło swoje poprawki trzech profesorów narodowości ukraińskiej pracujących na Wydziale Informatyki i Telekomunikacji Politechniki Krakowskiej, profesorowie Ihor Mykytyuk, Anatolij Prykarpatski i Yosyf Piskozub. Wśród osób, którym należą się szczególne podziękowania, są także Agnieszka Łyczko i dr Monika Herzog. W nadchodzącym semestrze kurs – podobnie jak jego bliźniacza polsko-angielska wersja – zostanie w pełni udźwiękowiony i zilustrowany. Pracują nad tym Adam Gruszczyński i Wojciech Jakubiec.
Mamy nadzieję, że kurs okaże się przydatny Ukraińcom uczącym się matematyki po angielsku, jesteśmy też otwarci na sugestie zmian i poprawek. Ukraińsko-angielskie kursy słownictwa matematycznego zostały udostępnione na platformach Memrise i Quizlet.
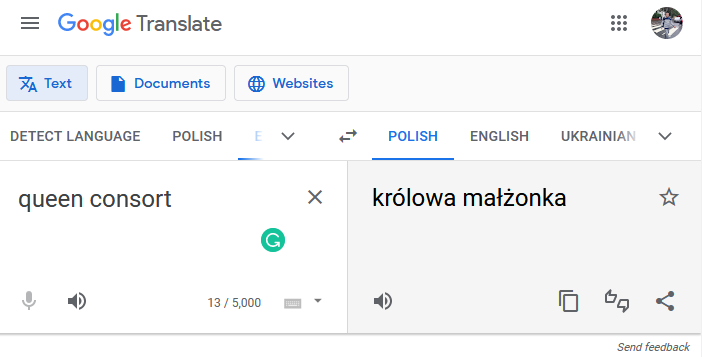
Po śmierci królowej Elżbiety II i objęciu tronu przez Karola III z licznym mediów dowiedzieć się można, że u boku nowego monarchy stoi „Królowa Konsorcjum”, Kamila. Serio?
Rozumiem jeszcze, że o brytyjskiej rodzinie królewskiej piszą obecnie wszyscy, nie tylko ludzie, którzy się tym tematem zajmowali regularnie i wiedzą, że Elżbieta II podczas swojego wielkiego Jubileuszu wyraziła życzenie, by Kamila, druga żona ówczesnego Księcia Walii Karola, nosiła po jej śmierci tytuł królowej małżonki. Rozumiem też, że wśród dziennikarzy pewnego pokolenia termin „królowa małżonka”, oznaczający żonę panującego króla, może być mniej znany niż „królowa matka”.
Ale że ktoś pisze bezmyślnie „Królowa Konsorcjum” i nie zauważy, że to po prostu bez sensu i brzmi głupio? Jakiego Konsorcjum? Jak zwykle, Tłumacz Google okazuje się być mądrzejszy…
W ramach dywersyfikacji źródeł informacji staram się regularnie czerpać z bardzo różnych mediów. Nie tylko polskich, amerykańskich, brytyjskich, francuskich czy niemieckich, oglądam czasem telewizję ukraińską (w Polsce stało się to dość łatwe w ostatnim czasie, bo trafiła do wszystkich kablówek, a nawet do naziemnego multiplexu), rosyjską (to akurat wymaga teraz odrobiny akrobacji i wiedzy), nie stronię też od telewizji arabskiej i chińskiej, chociaż po angielsku.
I właśnie anglojęzyczna telewizja chińska zaskoczyła mnie niedawno obwieszczając, że głowy dwóch państw spotkały się wirtualnie, „the presidents met virtually”. Wzdrygnąłem się słysząc to zdanie, choć okazało się, że nie miałem racji. Tak jak można mieć „a virtual meeting”, tak można się „meet virtually”, spotkać wirtualnie. Fraza ta występuje pospolicie w języku angielskim, niedawno użył jej prezydent Stanów Zjednoczonych w jednym ze swoich tweetów, jest całkowicie poprawna, nawet jeśli wydawała mi się mniej naturalna niż „met online”, „had a video conference”, „had a Skype call”, „spoke via Zoom”, „talked on Skype”, „had a Zoom meeting” itp.
Moment później na pasku chińskiej telewizji pojawiło się jednak coś, co ewidentnie nie powinno się było pojawić. Może nie dlatego, że było niepoprawne, ale było zdecydowanie niejednoznaczne. „The presidents meet virtually every Friday” to komunikat, który nabiera jednoznaczności dopiero wtedy, gdy ktoś przeczyta go na głos z taką czy inną intonacją. W wersji pisanej nie mamy pojęcia, czy prezydenci spotykają się online co piątek, czy spotykają się – osobiście lub za pośrednictwem internetu, nie wiadomo – w prawie każdy piątek.
„Virtually” to po angielsku nie tylko „wirtualnie”. To także „niemal”, „niemalże”, „prawie”, „nie całkiem”, nie do końca”, w pewnych kontekstach „dosłownie”. Ba, słownik Cambridge podaje to drugie znaczenie w pierwszej kolejności, dopiero w drugim znaczeniu wspomina o załatwianiu spraw za pośrednictwem internetu.
Nauczyłem się czegoś z telewizji chińskiej, jednocześnie wygląda na to, że i oni mają się jeszcze czego uczyć. A dywersyfikację źródeł informacji szczerze polecam, zwłaszcza w dzisiejszych czasach. Trzeba próbować wyjść ze swojej bańki, inaczej nie ma szans, by cokolwiek zrozumieć.